十行代码构建实时更新的宽表
发布日期:2024-12-15 04:24 点击次数:65
通过预计算和动态更新查询结果,显著提升了复杂查询的性能和实时性,支持快速决策和即时响应,常结合流式计算引擎、高性能数据库和增量更新机制实现高效维护。而如何构建更高效的物化视图,来自数据领域的 10 年资深架构师带来了他的经验分享。
作者 | 唐建法、Umer

什么是实时更新的物化视图?
物化视图(Materialized View),在数据管理系统中指将视图的查询和计算的结果保存为一个物理表,这样每次访问视图时,无需重新执行查询,从而提高了查询效率。物化视图针对一些需要做大量频繁的聚合计算,以及复杂关联的场景下,是一个非常行之有效的提高性能降低资源使用的数据架构模式。
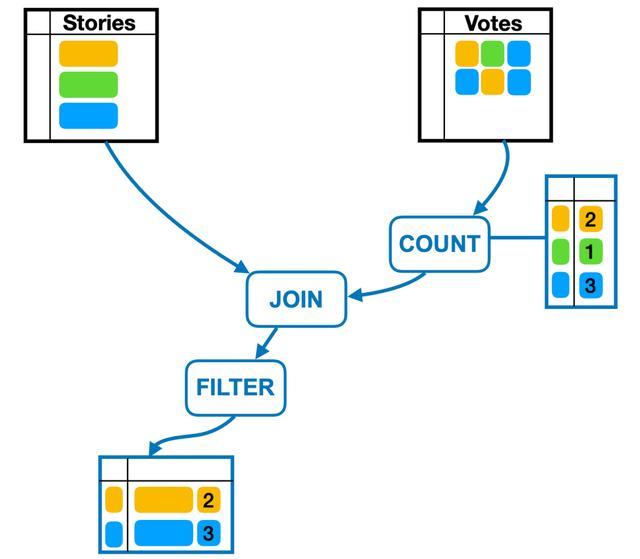
图片来源:https://blog.the-pans.com/caching-partially-materialized-views-consistently/
取决于视图的更新模式,可以分为全量更新的和实时(增量)更新的两种。
全量更新
全量更新策略在每次更新时都会清除物化视图中现有的所有数据,并将最新的查询结果集重新插入。这个过程可以理解为执行了 TRUNCATE TABLE 和 INSERT INTO SELECT 的组合操作。全量更新虽然简单直接,但在大数据量或高频更新的场景下,其效率和资源消耗可能成为一个问题。
实时(增量)更新
增量更新策略则更为高效,它仅针对自上次更新以来发生变化的数据部分计算物化视图的差异,并将这些差异应用到物化视图中。增量更新能以更少的资源消耗,提供一个更为实时的数据体验。

实时更新物化视图的适用场景
我们周围有很多业务场景需要视图提供当前的状态,例如:
1. 金融交易系统中的余额更新
在金融系统中,用户的账户余额会频繁变动(如存款、取款、转账、投资等操作)。为了在用户每次交易后,能够实时查看其账户总的余额,通常会使用实时更新的物化视图来确保用户在执行交易后,能够立刻查询到最新的账户状态。
场景需求:
交易完成后,用户能够实时看到余额变化。
数据一致性要求高,不能有延迟。
2. 库存管理系统中的实时库存
在电商平台或仓储系统中,库存的实时管理非常关键。每次销售、退货、补货都需要及时反映到系统中,以避免超卖或库存不足的问题。特别是在使用多平台进行销售时,使用多源汇聚及实时更新的物化视图可以确保在每次库存变更后,系统展示给用户的库存信息是最新的。
场景需求:
每次销售或退货时,库存信息需要立即更新。
防止超卖,确保用户查询时显示的是准确的库存数据。
3. 实时监控和告警系统
在一些生产系统或 IT 监控平台中,监控指标(如 CPU 利用率、内存占用、网络流量等)会频繁变化。此类系统需要根据实时数据判断是否触发告警。因此,可以通过实时更新技术来随时更新指标的物化视图,以便立即发现异常情况并触发告警。
场景需求:
需要对系统各项关键指标进行实时监控。
任何异常都需要在最短时间内被发现,并触发相应的告警机制。
4. 客户关系管理(CRM)系统中的实时客户状态
在 CRM 系统中,客户的行为数据(如打电话、发邮件、订单记录等)经常发生变动。业务人员希望能够实时看到客户的最新互动记录、订单状态等,以便根据最新情况及时跟进客户。因此, 在每次客户数据更新时刷新物化视图,使得业务人员在查看客户详情时能够看到最新信息。
场景需求:
业务人员在跟进客户时,必须基于最新的互动记录进行操作。
任何客户状态变更都要实时反映,以便做出及时决策。
5. 实时推荐系统中的用户行为数据更新
在电商或内容平台的推荐系统中,用户的行为(如点击、浏览、购买等)会实时影响推荐的结果。为了保证推荐结果的实时性,系统可以在每次用户行为数据变更后,使用实时更新物的化视图,从而使推荐系统能根据最新的用户行为数据生成推荐内容。
场景需求:
用户行为频繁,推荐结果需要实时调整。
数据必须实时反映用户的最新兴趣和偏好。

实时更新物化视图的实现方式
实时更新物化视图的实现方式,可以分为两大类别:
利用数据库提供的物化视图实时更新能力, 如 Oracle、PosgreSQL 等均提供相应的能力;
使用支持 CDC 数据复制和流式计算的实时数据平台,如 Kafka、TapData 等。
我们先来看一下第一类,不依赖于第三方组件,直接使用数据库的能力。
基于数据库自身能力的物化视图实时更新模式
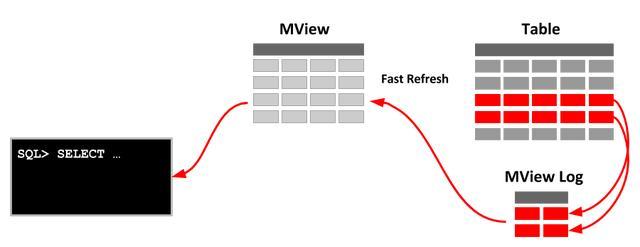
图片来源:https://oracle-base.com/articles/misc/materialized-views
1. Oracle Database
Oracle 通过物化视图(Materialized View)以及物化视图日志(Materialized View Log)来支持基于事务提交的实时刷新。
物化视图日志(Materialized View Log):Oracle 需要在源表上建立一个日志表,记录所有的插入、更新和删除操作。物化视图会根据日志来实时刷新数据。
在创建物化视图时,可以使用 REFRESH FAST ON COMMIT 选项,这样物化视图会在事务提交时根据日志数据进行增量刷新。如:
CREATE MATERIALIZED VIEW mv_exampleREFRESH FAST ON COMMIT AS SELECT * FROM source_table;
2. PostgreSQL
PostgreSQL 可以通过触发器(Trigger)来模拟这一功能。在事务提交时,触发器可以用来更新物化视图。
触发器:可以为源表创建 AFTER INSERT、AFTER UPDATE 或 AFTER DELETE 的触发器,确保当数据表发生变化时,自动执行刷新物化视图的操作。
CREATE OR REPLACE FUNCTION refresh_materialized_viewRETURNS TRIGGER AS BEGIN REFRESH MATERIALIZED VIEW mv_example;RETURN NEW;END; LANGUAGE plpgsql;
定时器(pg_cron):对于较为频繁的更新,也可以通过定时任务实现定期刷新。
CREATE TRIGGER refresh_mv_triggerAFTER INSERT OR UPDATE OR DELETEON source_tableFOR EACH STATEMENTEXECUTE FUNCTION refresh_materialized_view;
3. MySQL
MySQL 并不原生支持物化视图的概念,但可以通过触发器和表复制来模拟物化视图功能,配合触发器实现类似实时更新的效果。
触发器:在源表上创建触发器,每当发生数据变更时更新对应的派生表,模拟物化视图刷新。
复制表:创建一个冗余表,手动更新该表以反映源表中的变化。通过触发器自动进行更新。
CREATE TRIGGER refresh_mv_triggerAFTER INSERT ON source_table FOR EACH ROWBEGIN-- 手动更新物化视图逻辑END;
4. Snowflake
Snowflake 提供了一种称为 Materialized Views 的特性,可以为大规模数据集实现增量刷新。虽然 Snowflake 没有提供 On Commit Refresh 的功能,但它可以通过自动刷新实现接近实时的数据更新。
Materialized View:Snowflake 会自动检测源表的更改,并在需要时对物化视图进行增量刷新。刷新过程异步进行,因此在事务提交后会稍有延迟。
示例:
CREATE MATERIALIZED VIEW mv_exampleAS SELECT column1, COUNT(*)FROM source_table;
5. ClickHouse
ClickHouse 提供了一种基于物化视图(Materialized Views)的机制,能够实现对实时数据的近实时处理。通过依赖表自动触发物化视图的更新。
物化视图(Materialized Views):ClickHouse 允许将数据表的实时更新映射到物化视图,使用 POPULATE 选项将源表的数据推送到物化视图。
分布式流处理:ClickHouse 通过流处理机制对数据进行处理,适合对大量实时数据进行快速分析。
CREATE MATERIALIZED VIEW mv_exampleTO target_tableAS SELECT * FROM source_table;
6. BigQuery
Google BigQuery 支持物化视图(Materialized View),这些视图并不会在每次数据更改时自动更新,但支持周期性刷新。对于部分业务需求,可以通过触发刷新机制,在数据提交时强制刷新物化视图,达到类似实时更新的效果。
周期性刷新:BigQuery 支持每 30 分钟自动刷新物化视图,此外还可以通过编程接口(如 Google Cloud Functions)手动触发刷新。
CREATE MATERIALIZED VIEW mv_exampleAS SELECT column1, COUNT(*)FROM source_table;
我们可以看到,除了 Oracle 数据库提供了原生的基于事务级别实时更新视图能力之外,其他的都是通过触发器,或者定时自动刷新的方式来模拟。对实时要求比较高的场景,支持上并不理想。
另外,使用数据库自身能力也意味着你只能在数据库内部创建物化视图,对多源,跨库,读写分离,以及不希望给原库增加压力的场景,都无法使用这种模式。在这些时侯,我们需要使用一个支持 CDC 数据复制和流式计算的实时数据平台来实现
基于 CDC 数据复制和流式计算来实时更新物化视图
这种方案通常需要几个模块一起配合来完成,如:
CDC 实时复制工具,这个是用来对源库的事务日志进行监听、解析,并第一时间交给计算框架去处理。开源的一般会用 Debezium,商用的较常见的是Oracle Golden Gate 等。
流式计算能力,能够对 CDC 传输过来的 Insert / Update / Delete 同步到目标视图里面,并且能够对多表的事件进行关联聚合等。
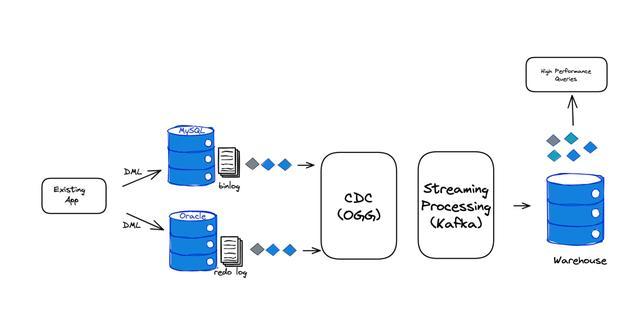
我们以一个订单宽表为例子来说明这个实现方式。我们有一个 MySQL 的电商平台,我们希望提供一个包含完整信息的订单 API(如客户信息,商品信息,物流信息等)提供给客户的手机端来查询。由于 MySQL 的并发查询和关联查询性能有限,我们选择了在能够提供相对较高查询性能,并支持 JSON 结构(API 模型设计)的 MongoDB 里构建一个物化视图的方式来支持这个 API。
换句话来说,假设这个是MySQL 数据库的表结构:
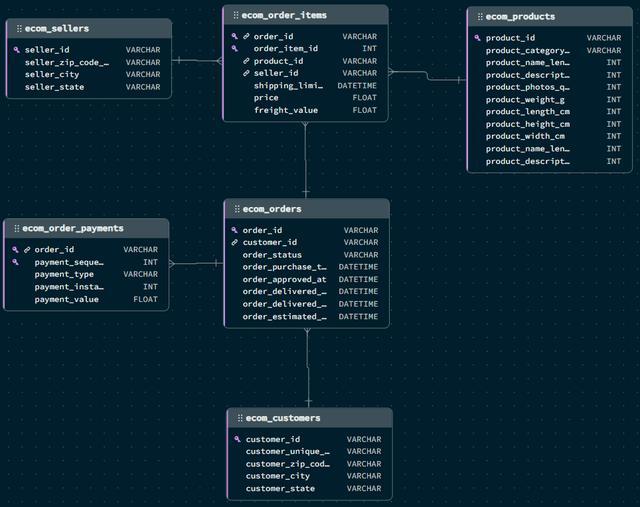
我们希望有这样的一个视图,可以直接用来给到客户端通过order_id 或者 customer_id 来查询客户订单。这个API JSON 的结构可能是下面这样,一个模型里包含了订单,客户地址,付款信息和订单明细。
{"_id": ObjectId("66f7e633f72882271da1a2ec"),"order_id": "0005a1a1728c9d785b8e2b08b904576c","customer_id": "16150771dfd4776261284213b89c304e","order_approved_at": "2018-03-20T18:35:21.000+00:00","order_delivered_carrier_date": "2018-03-28T00:37:42.000+00:00","order_delivered_customer_date": "2018-03-29T18:17:31.000+00:00","order_estimated_delivery_date": "2018-03-29T00:00:00.000+00:00","order_purchase_timestamp": "2018-03-19T18:40:33.000+00:00","order_status": "delivered"customer_info: {"customer_city": "santos","customer_id": "16150771dfd4776261284213b89c304e","customer_state": "SP","customer_unique_id": "639d23421f5517f69d0c3d6e6564cf0e","customer_zip_code_prefix": "11075"},order_items: [{"order_item_id": 1,"price": 145.9499969482422,"product_id": "310ae3c140ff94b03219ad0adc3c778f","order_id": "0005a1a1728c9d785b8e2b08b904576c","freight_value": 11.649999618530273,"seller_id": "a416b6a846a11724393025641d4edd5e","shipping_limit_date": "2018-03-26T18:31:29.000+00:00","seller": {"seller_city": "sao paulo","seller_id": "a416b6a846a11724393025641d4edd5e","seller_state": "SP","seller_zip_code_prefix": "03702"},"product": {"product_category_name": "beleza_saude","product_description_lenght": 493,"product_description_length": ,"product_height_cm": 12,"product_id": "310ae3c140ff94b03219ad0adc3c778f","product_length_cm": 30,"product_name_lenght": 59,"product_name_length": ,"product_photos_qty": 1,"product_weight_g": 2000,"product_width_cm": 16}},.........]}
为了达到这个效果,我们需要将订单表(ecom_orders)与订单明细表 (ecom_order_items),、客户信息表(ecomm_customer,形成一个宽表(OrderView),并使用 MySQL Debezium Connector + Kafka Connect + kakfa broker + Kafka Streams 实现持续刷新,这里将会介绍一个完整的步骤来达成这一目标。
方案步骤
先决条件
Docker(用于部署 Kafka、Zookeeper、Schema Registry 和 Kafka Connect)
所需的 Docker 镜像可从 Docker Hub(https://hub.docker.com/)下载。
Step 1:设置 Kafka Broker、Zookeeper、Schema Registry 和 Kafka Connect
name: kakfa-projectservices:zookeeper:image: bitnami/zookeeperports:- '31000:31000'environment:ZOOKEEPER_CLIENT_PORT: 2181ZOOKEEPER_TICK_TIME: 2000KAFKA_JMX_HOSTNAME: "localhost"ALLOW_ANONYMOUS_LOGIN: yesKAFKA_JMX_PORT: 31000
kafka:# "`-._,-'"`-._,-'"`-._,-'"`-._,-'"`-._,-'"`-._,-'"`-._,-'"`-._,-'"`-._,-# An important note about accessing Kafka from clients on other machines:# -----------------------------------------------------------------------## The config used here exposes port 9092 for _external_ connections to the broker# i.e. those from _outside_ the docker network. This could be from the host machine# running docker, or maybe further afield if you've got a more complicated setup.# If the latter is true, you will need to change the value 'localhost' in# KAFKA_ADVERTISED_LISTENERS to one that is resolvable to the docker host from those# remote clients## For connections _internal_ to the docker network, such as from other services# and components, use kafka:29092.## See https://rmoff.net/2018/08/02/kafka-listeners-explained/ for details# "`-._,-'"`-._,-'"`-._,-'"`-._,-'"`-._,-'"`-._,-'"`-._,-'"`-._,-'"`-._,-#image: bitnami/kafkaports:- '9092:9092'- '31001:31001'depends_on:- zookeeperenvironment:KAFKA_BROKER_ID: 1KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXTKAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT# Define both listenersKAFKA_LISTENERS: PLAINTEXT://0.0.0.0:29092,PLAINTEXT_HOST://0.0.0.0:9092# Match advertised listeners with the defined listenersKAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:29092,PLAINTEXT_HOST://localhost:9092KAFKA_AUTO_CREATE_TOPICS_ENABLE: "true"KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 100CONFLUENT_METRICS_ENABLE: 'false'KAFKA_JMX_HOSTNAME: "localhost"KAFKA_JMX_PORT: 31001schema-registry:image: confluentinc/cp-schema-registryports:- '8081:8081'environment:SCHEMA_REGISTRY_KAFKASTORE_BOOTSTRAP_SERVERS: "kafka:29092"SCHEMA_REGISTRY_HOST_NAME: "schema-registry"SCHEMA_REGISTRY_LISTENERS: "http://0.0.0.0:8081"
kafka-connect:image: confluentinc/cp-kafka-connect-baseports:- '8083:8083'- '31004:31004'environment:CONNECT_BOOTSTRAP_SERVERS: "kafka:29092"CONNECT_REST_PORT: 8083CONNECT_GROUP_ID: compose-connect-groupCONNECT_CONFIG_STORAGE_TOPIC: docker-connect-configsCONNECT_OFFSET_STORAGE_TOPIC: docker-connect-offsetsCONNECT_STATUS_STORAGE_TOPIC: docker-connect-statusCONNECT_KEY_CONVERTER: io.confluent.connect.avro.AvroConverterCONNECT_VALUE_CONVERTER: io.confluent.connect.avro.AvroConverterCONNECT_KEY_CONVERTER_SCHEMA_REGISTRY_URL: http://schema-registry:8081CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL: http://schema-registry:8081CONNECT_INTERNAL_KEY_CONVERTER: "org.apache.kafka.connect.json.JsonConverter"CONNECT_INTERNAL_VALUE_CONVERTER: "org.apache.kafka.connect.json.JsonConverter"CONNECT_REST_ADVERTISED_HOST_NAME: "kafka-connect"CONNECT_LOG4J_ROOT_LOGLEVEL: "INFO"CONNECT_LOG4J_LOGGERS: "org.apache.kafka.connect.runtime.rest=WARN,org.reflections=ERROR"CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: "1"CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: "1"CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: "1"CONNECT_PLUGIN_PATH: /usr/share/java,/usr/share/confluent-hub-componentsKAFKA_JMX_HOSTNAME: "localhost"KAFKA_JMX_PORT: 31004depends_on:- zookeeper- kafka- schema-registry
# run docker-compose.yml filedocker-compose up
Step 2:在 Kafka Connect 中安装 Debezium MySQL Connector
使用 Kafka Connect 容器中的 confluent-hub-client 安装 Debezium MySQL Connector:
docker exec -it kafka-connect /usr/bin/confluent-hub install debezium/debezium-connector-mysql:latest --component-dir /usr/share/confluent-hub-components --no-prompt
安装完成后,重启 Kafka Connect 容器:
docker restart kafka-connect
Step 3:部署 Debezium MySQL Connector
准备一个用于 MySQL 源连接器的 JSON 配置文件。以下是一个示例配置文件 (debezium-mysql.json):
{"name": "mysql-connector","config": {"connector.class": "io.debezium.connector.mysql.MySqlConnector","tasks.max": "1","database.hostname": "192.168.1.11","database.port": "3306","database.user": "root","database.password": "YJ983g!","snapshot.mode": "initial","database.server.id": "184054","database.server.name": "dbserver1.DEMO","table.include.list": "ECommerce.ecom_customers,ECommerce.ecom_orders,ECommerce.ecom_order_items","database.history.kafka.bootstrap.servers": "kafka:29092","database.history.kafka.topic": "dbhistory.fullfillment","topic.prefix": "dbserver1", // Add this line,"database.history.kafka.schema.registry.url": "http://schema-registry:8081","schema.history.internal.kafka.bootstrap.servers": "kafka:29092","schema.history.internal.kafka.topic": "umer-test-history-topic"}}
将该配置通过 Kafka Connect 的 REST API 部署连接器:
curl -X POST -H "Content-Type: application/json" --data @debezium-mysql.json http://localhost:8083/connectors
验证连接器状态,确保其处于运行状态(RUNNING):
curl http://localhost:8083/connectors/mysql-connector/status
{"name":"mysql-connector","connector":{"state":"RUNNING","worker_id":"kafka-connect:8083"},"tasks":[{"id":0,"state":"RUNNING","worker_id":"kafka-connect:8083"}],"type":"source"}
如果连接器状态显示为 RUNNING,则表示你的 MySQL 数据已经实时流入 Kafka Broker。MySQL 数据库中的每次更改(插入、更新、删除)都会被 Debezium MySQL Connector 捕获并发送至 Kafka Broker。
至此,你已成功完成从 MySQL 到 Kafka Broker 的实时数据流设置。
验证 Kafka Broker 中的 Kafka 主题是否正常。
docker exec -it kafka bashcd /opt/bitnami/kafka/bin./kafka-topics.sh --bootstrap-server localhost:9092 --list
__consumer_offsets_schemasdbserver1dbserver1.ECommerce.ecom_customersdbserver1.Commerce.ecom_itemsdbserver1.Commerce.ecom_ordersdocker-connect-configsdocker-connect-offsetsdocker-connect-statusumer-test-history-topic
Step 4:从 Kafka Broker 实时流式传输数据到 MongoDB
现在 MySQL 的数据已经实时流入 Kafka,你可以使用自定义的 Node.js 脚本消费这些数据并将其映射到 MongoDB。该应用程序使用 kafkajs 流式库从 Kafka 主题中消费消息,并使用 mongodb 库将数据存储到 MongoDB 中。
在本示例中,我们有一个包含订单、订单项以及客户详细信息的电商数据库。我们从 Kafka 主题中消费这些数据,在写入 MongoDB 之前,将订单数据与相关的客户信息和订单项进行丰富处理。
const { Kafka } = require('kafkajs');const { MongoClient } = require('mongodb');
const kafka = new Kafka({clientId: 'qa-01',brokers: ['192.168.1.11:9092'],sasl: {mechanism: 'plain',username: 'tapdata',password: 'VVVIy676!',},});
const mongoUrl = 'mongodb://root:NTUOi37$!@192.168.1.11:27017';const mongoClient = new MongoClient(mongoUrl, { useUnifiedTopology: true });
let db;const orders = new Map; // Map to temporarily store ordersconst customers = new Map; // Map to store customer info
async function connectMongo {try {await mongoClient.connect;db = mongoClient.db('orderSingleView');console.log("Successfully connected to MongoDB.");} catch (error) {console.error("Failed to connect to MongoDB:", error);}}
async function consumeEcomOrders {const ecomOrdersConsumer = kafka.consumer({ groupId: 'qa_orders_x1_topic_group60' });await ecomOrdersConsumer.connect;await ecomOrdersConsumer.subscribe({ topic: 'dbserver1.ecom_orders_topic', fromBeginning: true });await ecomOrdersConsumer.run({eachMessage: async ({ message }) => {const ecomOrderData = JSON.parse(message.value.toString);const orderId = ecomOrderData.order_id; // Adjusted to match your data structureconst mqOp = message.headers.mqOp.toString;
if (mqOp === 'delete') {await db.collection('orderSingleView').deleteOne({ order_id: orderId });orders.delete(orderId); // Remove from orders mapconsole.log(`Deleted Order with ID: ${orderId}`);} else {// Store order data in the Maporders.set(orderId, { ...ecomOrderData });console.log(`Inserted/Updated Order: ${JSON.stringify(ecomOrderData)}`);
// Insert the order into MongoDBawait db.collection('orderSingleView').updateOne({ order_id: orderId },{ $set: { ...ecomOrderData } },{ upsert: true });
// Check for customer info immediately after inserting the orderawait enrichOrderWithCustomerInfo(orderId, ecomOrderData.customer_id);}},});}
async function consumeEcomCustomersDetails {const customerConsumer = kafka.consumer({ groupId: 'qa_customers_x1_topic_group60' });await customerConsumer.connect;await customerConsumer.subscribe({ topic: 'dbserver1.ecom_customers_topic', fromBeginning: true });await customerConsumer.run({eachMessage: async ({ message }) => {const customerDetailData = JSON.parse(message.value.toString);const customerId = customerDetailData.customer_id; // Adjusted to match your data structureconst mqOp = message.headers.mqOp.toString;
if (mqOp === 'delete') {await db.collection('orderSingleView').updateMany({ 'customer_info.customer_id': customerId },{ $unset: { customer_info: "" } });console.log(`Deleted Customer Info for Customer ID: ${customerId}`);} else {// Store customer data in the Mapcustomers.set(customerId, customerDetailData);console.log(`Inserted/Updated Customer Info for Customer ID: ${customerId}`);
// Enrich existing orders if customer_id matchesawait enrichExistingOrders(customerId);}},});}
async function consumeOrderItems {const orderItemsConsumer = kafka.consumer({ groupId: 'qa_order_items_topic_group60' });await orderItemsConsumer.connect;await orderItemsConsumer.subscribe({ topic: 'dbserver1.ecom_order_items_topic', fromBeginning: true });await orderItemsConsumer.run({eachMessage: async ({ message }) => {const orderItemData = JSON.parse(message.value.toString);const orderId = orderItemData.order_id; // Get the order_id from order_itemconst mqOp = message.headers.mqOp.toString;
if (mqOp === 'delete') {// Remove the item from the order's items array in MongoDBawait db.collection('orderSingleView').updateOne({ order_id: orderId },{ $pull: { order_items: { order_id: orderItemData.order_id} } });console.log(`Deleted Order Item with ID: ${orderItemData.item_id} from Order ID: ${orderId}`);} else {// Insert or update the item in the order's items array in MongoDBconst result = await db.collection('orderSingleView').updateOne({ order_id: orderId },{ $addToSet: { order_items: orderItemData } }, // Use $addToSet to avoid duplicates{ upsert: false } // Don't create a new document if not found);
if (result.modifiedCount === 0) {console.log(`No existing order found for Order ID: ${orderId}, inserting as new order item`);// Optionally, you could handle this case as needed} else {console.log(`Inserted/Updated Order Item for Order ID: ${orderId}`);}}},});}
async function enrichExistingOrders(customerId) {for (const [orderId, order] of orders) {if (order.customer_id === customerId) {await enrichOrderWithCustomerInfo(orderId, customerId);}}}
async function enrichOrderWithCustomerInfo(orderId, customerId) {if (customers.has(customerId)) {const customerInfo = customers.get(customerId);try {await db.collection('orderSingleView').updateOne({ order_id: orderId },{ $set: { customer_info: customerInfo } });console.log(`Enriched Order with Customer Info for Order ID: ${orderId}`);} catch (error) {console.error(`Failed to enrich order ${orderId} with customer info: ${error.message}`);}} else {console.log(`No customer found for Customer ID: ${customerId}. Waiting for customer info...`);}}
(async => {await connectMongo;await consumeEcomOrders;await consumeEcomCustomersDetails;await consumeOrderItems; // Start consuming order items});
小结
使用 Debezium MySQL 连接器与 Kafka Connect 相结合,可以方便地将变更数据捕获(CDC)传输到 Kafka 代理。通过 Node.js 中的 Kafka Streams 库,可以执行实时数据流处理和转换。此配置会从 MySQL 数据库中捕获更新,实时处理这些更新,并在将数据结果存储到MongoDB之前对其进行转换和映射。

什么是 Tap Flow
Tap Flow 是一个 TapData 实时数据平台提供的一个流式数据采集和处理的框架。开发者可以使用 Tap Flow 来实现实时数据复制,实时数据加工处理,多表流式合并,构建实时更新的物化视图等技术场景。
使用上面同样的例子,我们来看看用 Tap Flow 会是怎样的一个体验:
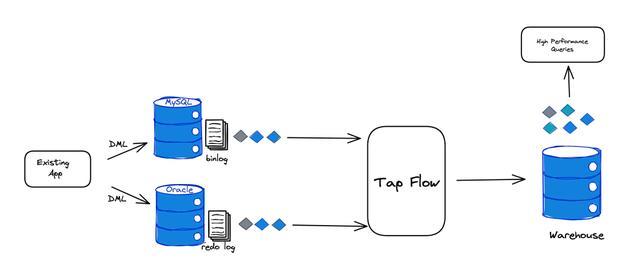
使用 Tap Flow 构建一个订单宽表
主要流程:
安装 Tap Flow 的 Python SDK 和CLI
配置 TapData Cluster 连接信息
使用 Tap Flow 的命令和 API,构建 Flow,并设置目标为一个物化视图
运行 Flow
详细步骤:
Step 1:安装 Tap Shell, 一个 Tap Flow 的 Python SDK 和交互式命令行界面
# prerequisites: install python3 & pip3 before install tapshell# Install TapShell using Pipmaximus@Reid:~/home pip3 install tapcli==0.2.5
Step 2:启动并配置 Tap Shell
# Enter tapcli directory and Type tap and press enter buttonmaximus@Reid:~/ tapMon Nov 4 12:34:48 CST 2024 Welcome to TapData Live Data Platform, Enjoy Your Data Trip !Tap Flow requires TapData Live Data Platform(LDP) cluster to run.If you would like to use with TapData Enterprise or TapData Community, type L to continue.If you would like to use TapData Cloud, or you are new to TapData, type C or press ENTER to continue.Please type L or C (L/[C]): CYou may obtain the keys by log onto TapData Cloud, and click: 'User Center' on the top right, then copy & paste the accesskey and secret key pair.Enter AK: xxxxxxxxxxxxxxxxxxxEnter SK: xxxxxxxxxxxxxxxxxxxMon Oct 21 15:53:50 CST 2024 connecting remote server: https://cloud.tapdata.net ...Mon Oct 21 15:53:50 CST 2024 Welcome to TapData Live Data Platform, Enjoy Your Data Trip !========================================================================================================================TapData Cloud Service Running Agent: 1Agent name: agent-jk6453h (Machine), ip: 192.168.1.11, cpu usage: 40%
tap >
# If you're using TapData Enterprise then type L, please provide the server URL with port and access code, for example: 192.18.108.1:13030 && 123e4567-e89b-12d3-a456-426614174000. You can find the access code by logging into the TapData Enterprise platform, then navigating to Account SettingsMon Nov 4 12:34:48 CST 2024 Welcome to TapData Live Data Platform, Enjoy Your Data Trip !Tap Flow requires TapData Live Data Platform(LDP) cluster to run.If you would like to use with TapData Enterprise or TapData Community, type L to continue.If you would like to use TapData Cloud, or you are new to TapData, type C or press ENTER to continue.Please type L or C (L/[C]): LPlease enter server:port of TapData LDP server: 127.0.0.1:3030Please enter access code: xxxxxxxxxxxxxxxxxxxxxxxxxxMon Oct 21 11:26:55 CST 2024 connecting remote server: you 127.0.0.1:3030 ...Mon Oct 21 11:26:55 CST 2024 Welcome to TapData Live Data Platform, Enjoy Your Data Trip !
tap >
Step 3:开始构建物化视图
Step 3.1:设置与源数据库的连接
# Connect with Source Database Mysqltap > mysqlJsonConfig = {'database': 'Demo','port': 3306,'host': 'demo.tapdata.io','username': 'demouser','password': 'demopass'};tap > mysqlConn = DataSource('mysql', 'qa-mySqlEcommerceData', mysqlJsonConfig).type('source').save;datasource qa-mySqlEcommerceData creating, please wait...save datasource qa-mySqlEcommerceData success, will load schema, please wait...load schema status: finished
# Connect with Target Database Mongodbtap > mongodbJsonConfig = {"uri": "mongodb://john:doe@192.168.0.1:27017/orderSingleView?authSource=admin"}tap > mongodbConn = DataSource("mongodb", "qa-mongodbOrderView", mongodbJsonConfig).type("target").save;
datasource qa-mongodbOrderView creating, please wait...save datasource qa-mongodbOrderView success, will load schema, please wait...load schema status: finished
Step 3.2:创建数据管道以构建宽表订单数据模型
# Create the flow and set the base or master table "ecom_orders"tap> orderFlow = Flow("Order_SingleView_Sync").read_from("qa-mySqlEcommerceData.ecom_orders");Flow updated: source added
# Lookup and add the 'ecom_customers' table as an embedded document in 'orders' using customer_id as the association key.cIn MongoDB, path="customer_info", embeds it with the field name customer_info, and type="object", indicating it will be stored as an embedded document.tap> orderFlow.lookup("qa-mySqlEcommerceData.ecom_customers", path="customer_info",type="object", relation=[["customer_id","customer_id"]]);Flow updated: source addedFlow updated: new table added as child table
# Lookup and add the 'ecom_order_payments' table as an embedded array in 'orders' using order_id as the association key. In MongoDB, path="orderPayments" embeds it with the field name order_payments, and type="array", indicating it will be stored as an embedded array.tap> orderFlow.lookup("qa-mySqlEcommerceData.ecom_order_payments", path="order_payments",type="array", relation=[["order_id","order_id"]]);Flow updated: source addedFlow updated: new table added as child table
# Lookup and add the 'ecom_order_items' table as an embedded array in 'orders' using order_id as the association key. In MongoDB, path="order_items," embeds it with the field name order_items, and type="array", indicating it will be stored as an embedded array.tap> orderFlow.lookup("qa-mySqlEcommerceData.ecom_order_items", path="order_items",type="array", relation=[["order_id","order_id"]]);
Flow updated: source addedFlow updated: new table added as child table
# Lookup and add the 'ecom_products' table as embedded document in 'order_itmes' using product_id as association key.tap> orderFlow.lookup("qa-mySqlEcommerceData.ecom_products", path="order_items.product",type="object", relation=[["product_id","order_items.product_id"]]);
Flow updated: source addedFlow updated: new table added as child table
## Lookup and add the 'ecom_sellers' table as embedded document in 'order_itmes' using seller_id as association key.tap> orderFlow.lookup("qa-mySqlEcommerceData.ecom_sellers", path="order_items.seller",type="object", relation=[["seller_id","order_items.seller_id"]]);
Flow updated: source addedFlow updated: new table added as child table
# Write to a collection in MongoDB to become a materialized viewtap> orderFlow.write_to("qa-mongodbOrderView.orderSingleView");
Flow updated: sink added
Step 3.3:启动数据管道
# Start data flowtap> orderFlow.start;Order_SingleView_Sync Pipeline is running
Step 3.4:查看数据流统计
# view Flow statstap> stats Order_SingleView_Sync

Step 3.5:在 MongoDB 中查看宽表订单数据模型
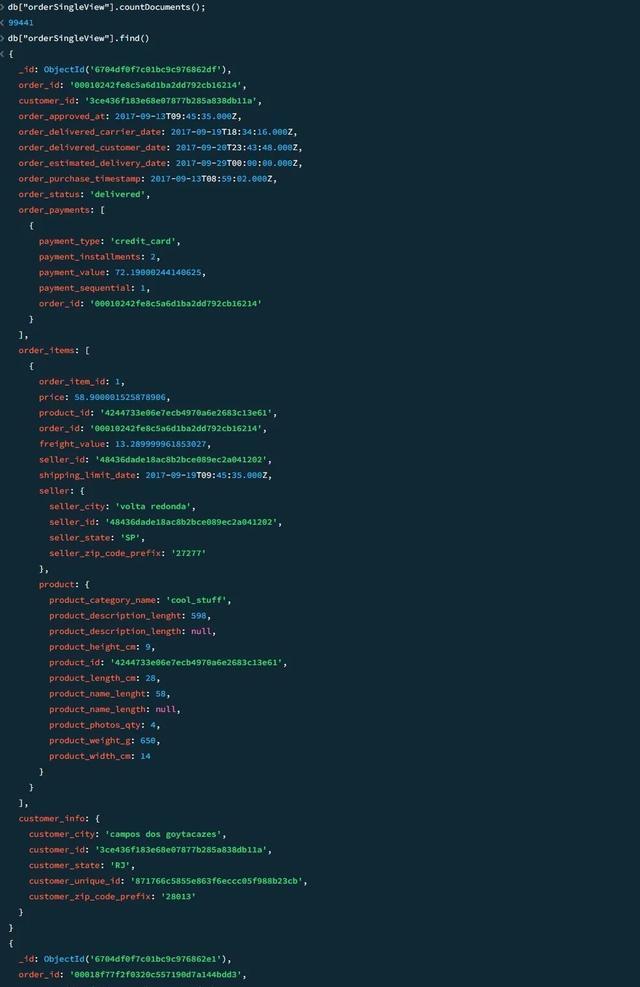
验证物化视图的实时更新效果
运行脚本,观察mysql 库的订单数据变动
- 在源库新增订单
Use ECommerceData;
select count(*) from ecom_orders eo;
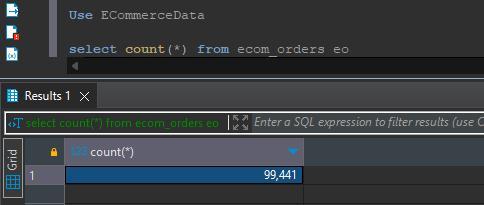
执行下述脚本在 ecom_orders table 里新增记录:
DELIMITER //CREATE PROCEDURE InsertRandomOrdersBEGINDECLARE i INT DEFAULT 0;-- Disable foreign key checksSET FOREIGN_KEY_CHECKS = 0;
WHILE i < 10 DOINSERT INTO ECommerceData.ecom_orders(order_id, customer_id, order_status, order_purchase_timestamp,order_approved_at, order_delivered_carrier_date,order_delivered_customer_date, order_estimated_delivery_date)VALUES(CONCAT('ORD_I_', UUID), -- Adds 'ORD_' before the randomly generated order_idUUID, -- Generates a random customer_idCASEWHEN RAND < 0.3 THEN 'delivered'WHEN RAND < 0.6 THEN 'shipped'ELSE 'processing'END, -- Random order statusNOW - INTERVAL FLOOR(RAND * 365) DAY, -- Random order purchase date within the last yearNOW - INTERVAL FLOOR(RAND * 300) DAY, -- Random approved date within the last 300 daysNOW - INTERVAL FLOOR(RAND * 200) DAY, -- Random carrier delivery date within the last 200 daysNOW - INTERVAL FLOOR(RAND * 100) DAY, -- Random customer delivery date within the last 100 daysNOW + INTERVAL FLOOR(RAND * 30) DAY -- Random estimated delivery date within the next 30 days);SET i = i + 1;END WHILE;-- Re-enable foreign key checksSET FOREIGN_KEY_CHECKS = 1;END//DELIMITER ;
CALL InsertRandomOrders;
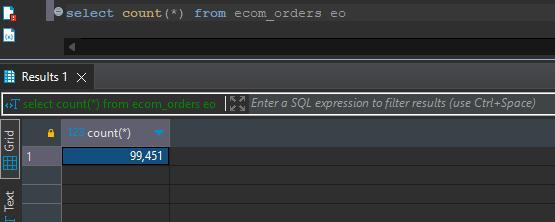
select count(*) from ecom_orders eo;
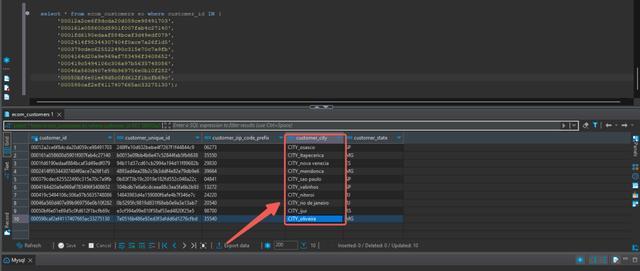
客户城市更新:更新客户的城市名称,并在城市名称前添加“CITY_”
- 请执行以下脚本以更新并在 ecom_customer 表的 city_name 字段中添加前缀:
DELIMITER //CREATE PROCEDURE UpdateCustomerCityBEGIN-- Disable autocommitSET autocommit = 0;
-- Update customer_city by adding the prefix 'CITY_' for the specified customer_idsUPDATE ECommerceData.ecom_customersSET customer_city = CONCAT('CITY_', customer_city)WHERE customer_id IN ('00012a2ce6f8dcda20d059ce98491703','000161a058600d5901f007fab4c27140','0001fd6190edaaf884bcaf3d49edf079','0002414f95344307404f0ace7a26f1d5','000379cdec625522490c315e70c7a9fb','0004164d20a9e969af783496f3408652','000419c5494106c306a97b5635748086','00046a560d407e99b969756e0b10f282','00050bf6e01e69d5c0fd612f1bcfb69c','000598caf2ef4117407665ac33275130');
-- Commit the transaction to save the changesCOMMIT;
-- Re-enable autocommitSET autocommit = 1;END//DELIMITER ;
call UpdateCustomerCity
- 执行以下查询以查看 ecom_customer 表中的更新:
select * from ecom_customers eo where customer_id IN ('00012a2ce6f8dcda20d059ce98491703','000161a058600d5901f007fab4c27140','0001fd6190edaaf884bcaf3d49edf079','0002414f95344307404f0ace7a26f1d5','000379cdec625522490c315e70c7a9fb','0004164d20a9e969af783496f3408652','000419c5494106c306a97b5635748086','00046a560d407e99b969756e0b10f282','00050bf6e01e69d5c0fd612f1bcfb69c','000598caf2ef4117407665ac33275130');
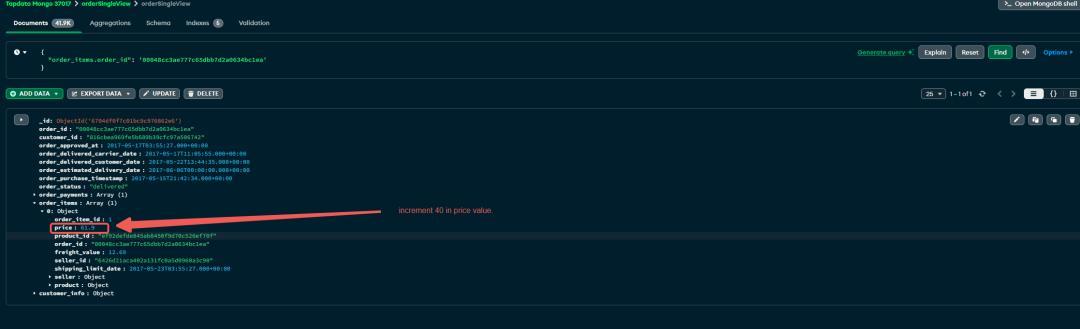
订单明细的变化
- 在 order_items 表中,order_id 为 '00048cc3ae777c65dbb7d2a0634bc1ea' 的记录,其 price 值为 21.9。

- 在 order_details 表中,将 price 小于 200 的记录的 price 值增加 40:
DELIMITER //
CREATE PROCEDURE UpdatePricesBEGIN-- Update price by adding 40 where price is less than 200UPDATE ECommerceData.ecom_order_itemsSET price = price + 40WHERE price < 200;
-- Commit the changesCOMMIT;END//DELIMITER ;
call UpdatePrices;
执行以下查询以查看更新后的价格,验证脚本是否生效
select * from ECommerceData.ecom_order_items where order_id = '00048cc3ae777c65dbb7d2a0634bc1ea'

观察 Order View 对上述更改的更新情况:
- 运行以下查询检查 MongoDB 中订单的总数。总数现在应为 99,451,因为我们通过脚本新增了 10 条记录。在通过脚本新增记录之前,总数为 99,441。

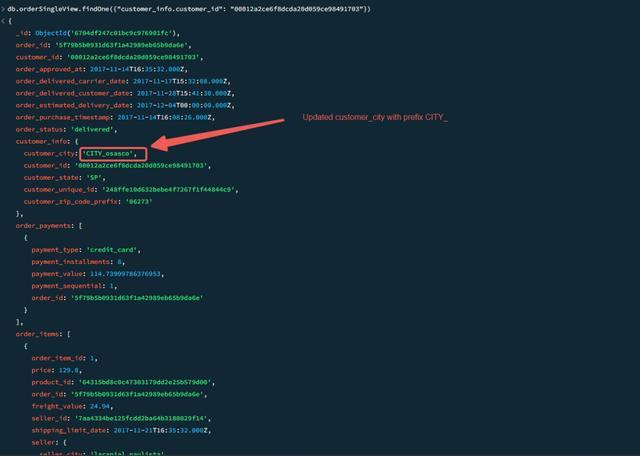
- 验证 MongoDB 宽表集合中的 customer_info 文档更新情况
db.orderSingleView.findOne({"customer_info.customer_id": "00012a2ce6f8dcda20d059ce98491703"})
- 验证 MongoDB 宽表集合中 order_items 数组的更新情况
db.orderSingleView.findOne({"order_items.order_id": '00048cc3ae777c65dbb7d2a0634bc1ea'});

小结
TapFlow 是一个编程框架,目前还处于 Preview 状态。它允许用户执行实时数据复制、数据处理以及创建物化视图等操作。它由一组 API、Python SDK 以及Tap CLI(一个命令行实用程序)组成。和常见的实时数据管道或者集成方案(如Kafka ETL)相比,Tap Flow 内部直接集成了 CDC,不再需要额外的一个模块,同时它是基于 Python / JS 脚本语言,能够快速实现各种数据处理需求,且支持大部分主流国产数据库。
作者介绍:
唐建法(TJ),TapData 创始人兼 CEO,10 年数据架构师,3 年产品创业人,曾任 MongoDB 大中华区首席架构师,MongoDB 中文社区主席。
Muhammad Umer Riaz,TapData 售前解决方案工程师
- 上一篇:没有了
- 下一篇:没有了